On 16 February, a group of researchers published a rapid response in the BMJ in which they heavily criticized the NICE committee that is working on a new guideline for myalgic encephalomyelitis/chronic fatigue syndrome (ME/CFS). They accuse the NICE committee of “a disastrous misapplication of GRADE methodology.” This blog post explains why this critique is unfounded.

Who are the authors?
The first of 11 authors of the rapid response is Jason Busse, an associate professor at McMaster University. There are, however, some more familiar names such as Professor Paul Garner, Director of the Centre for Evidence Synthesis in Global Health and Co-ordinating Editor of the Cochrane Infectious Diseases Group. Garner previously wrote about his struggles with persistent symptoms following COVID-19. He explained that he once met ME/CFS diagnostic criteria but that he recovered by overcoming his fear of exercise and by “understanding that our unconscious normal thoughts and feelings influence the symptoms we experience.”
Another recognizable name is Signe Agnes Flottorp, Research director of the Norwegian Institute of Public Health. Flottorp recently was at the center of controversy when she defended research into the Lightning Process, a non-medical training program that combines concepts from Neuro-Linguistic Programming, Life Coaching, and Osteopathy. Critics have denounced the Lightning Process as pseudoscience or quackery.
Other authors of the rapid response are known for their leadership in evidence-based medicine. The most important name in this regard is Canadian Professor Gordon Guyatt. Guyatt was one of the authors of the GRADE handbook.
What is GRADE?
GRADE stands for Grading of Recommendations Assessment, Development, and Evaluation. It’s a common and transparent approach to grading quality of evidence and strength of clinical recommendations. The NICE committee made use of this approach but Busse and colleagues criticize them for “a disastrous misapplication of GRADE methodology.”
The 11 authors focus on the evidence supporting graded exercise therapy (GET). They argue that the NICE guideline committee has chosen to downplay the evidence of GET for patients suffering from ME/CFS. They wrote:
“An appropriate application of GRADE would have come to a very different conclusion, as did a recent Cochrane review of exercise in chronic fatigue syndrome using GRADE methodology: ‘Exercise therapy probably reduces fatigue at end of treatment (SMD −0.66, 95% CI −1.01 to −0.31; 7 studies, 840 participants; moderate‐certainty evidence)’.”
In this blog, I will analyze each of the arguments made by Busse and colleagues step by step.
The Cochrane review versus the NICE report
I should probably start by explaining that the Cochrane review Guyatt and colleagues cite as an ‘appropriate’ application of GRADE, is quite controversial. It previously overstated the evidence for GET and was amended after a formal complaint and an internal review by Cochrane. The review is currently being updated following further concerns about its methodology. Cochrane’s Editor-in-Chief, Dr. Karla Soares-Weiser explained that “this amended review is still based on a research question and a set of methods from 2002, and reflects evidence from studies that applied definitions of ME/CFS from the 1990s.” The review might not be the best example of how to assess the evidence on GET for ME/CFS.
But let’s set those issues aside for a moment and compare the amended Cochrane review to the draft report by the NICE committee. The NICE committee rated the quality of evidence for GET as low to very low. The Cochrane review also rated the quality of evidence in support of GET as low to very low with the sole exception of post-treatment fatigue where the quality of evidence was rated as ‘moderate’. The differences between both assessments were thus rather small. The data Busse and colleagues cite (post-treatment fatigue) is the one notable exception where the Cochrane review didn’t rate the evidence in support of GET as low or very low quality. The review included data on physical functioning, pain, sleep, quality of life, depression, anxiety and for all those outcomes the quality of evidence was rated as low or very low.
Even for fatigue measured at follow-up, the Cochrane review rated the quality of evidence as very low. These follow-up assessments are important because they formed the primary outcome in the biggest GET-trials that provide most of the data in the review. The majority of the data on post-treatment fatigue that Guyatt and colleagues highlight, came from interim assessments.
This gives the impression that Busse and colleagues cherry-picked a particular outcome to highlight differences between the Cochrane review and the NICE report. Let’s, however, take a look at the reasons why the NICE guideline committee might have rated this particular outcome differently.
Heterogeneity
The Cochrane review compared many different forms of exercise therapy in one statistical meta-analysis. In the trial by Wallman et al., for example, patients could reduce their activity level if exercise made them feel unwell while other forms of GET were strictly time-contingent. The trial by Jason et al. used anaerobic exercise, while others focused on aerobic exercise. The FINE trial did not prescribe GET but ‘pragmatic rehabilitation’, an intervention that was delivered by nurses at home. The trial by Powell et al. tested exercise therapy combined with patient education based on cognitive-behavioral principles. By combining these different interventions in one meta-analysis, the estimates found in the Cochrane review suffered from high heterogeneity.
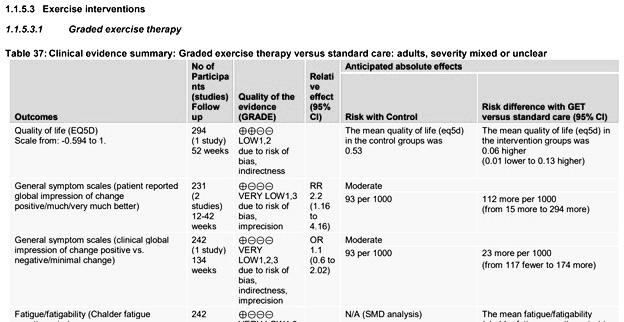
In a comment to the Cochrane review, I have previously argued that the quality of evidence for post-treatment fatigue should be downgraded because it also suffered from “extensive heterogeneity” (I2 = 94 %). The NICE committee, however, chose a different solution. It made greater differentiation between these different forms of exercise therapy by performing multiple meta-analyses.
Busse et al. criticize the NICE committee because “their guideline does not provide a GRADE evidence summary of findings table for fatigue related to exercise interventions.” This is incorrect. NICE provided hundreds of pages with additional documentation that contain GRADE summary tables for all outcomes and interventions. They have simply grouped the trials differently than the Cochrane review.
Imprecision
Sometimes studies include few patients resulting in a wide confidence interval (CI) around the estimate of the effect. The GRADE handbook suggests downgrading for imprecision “if a recommendation would be altered if the lower versus the upper boundary of the CI represented the true underlying effect.”
This might need some further explanation. Suppose a meta-analysis with an estimate that suggests the intervention is useful for patients. The intervention might, for example, cause a reduction in fatigue that looks worthwhile; big enough to recommend the treatment in a clinical guideline. It remains unsure, however, if that estimate reflects the true underlying effect. Perhaps it was based on a limited amount of data, resulting in a wide confidence interval. The lower bound of that confidence interval might be so small that, if this was the true underlying effect, the treatment would no longer be recommended. In such a case, GRADE recommends downgrading the quality of evidence.
The big question here is: what is the clinical decision threshold? What value can be considered too small so that it is no longer worthwhile to recommend the intervention? Researchers often use an estimate of the minimal important difference (MID): the smallest difference on a particular outcome measure that would make a clinically important difference for patients. If the lower bound of the confidence interval is lower than the MID, then one can downgrade for imprecision. This is exactly what the NICE committee did. It downgraded for imprecision when a confidence interval crossed the MID.
Busse and colleagues, however, argue that researchers should not downgrade for imprecision if the lower boundary of the confidence interval is bigger than 0.2 standard deviations. They do not clarify, however, why such a small effect should be regarded as the clinical decision threshold. MID estimates are usually larger than 0.2 standard deviations (they are often close to 0.5 standard deviations). Additionally, fatigue questionnaires that were used as the primary outcome, were also used to define inclusion criteria in some GET trials. This results in lower standard deviations than would normally be the case and can inflate treatment effects.
The choice of a clinical decision threshold is always a bit arbitrary but it seems that the NICE guideline committee has come up with a better-substantiated threshold than what Busse et al. propose.
Indirectness of evidence
Sometimes there is evidence for the effectiveness of an intervention but on a different patient population than the one the guideline is intended for. According to GRADE methodology, this is another reason to downgrade the quality of evidence and that is indeed what the NICE committee did with the evidence on GET.
Following a 2015 report by the National Academy of Medicine, the NICE committee regard post-exertional malaise (PEM) – a worsening of symptoms following exertion – as a characteristic feature of ME/CFS. Trials on GET, however, used case definitions, such as the Oxford and Fukuda criteria, that were created in the 1990s and that do not require patients to experience PEM. The committee agreed that a population diagnosed with such criteria may not accurately represent the ME/CFS population and that people experiencing PEM might respond differently to treatment than those who do not experience it. It therefore decided to downgrade the evidence for population indirectness. This is in agreement with other systematic reviews, which also differentiate between case definitions that require PEM and those that do not.
Busse and colleagues argue against downgrading. They refer to the Cochrane review on GET which performed a subgroup analysis showing “little or no difference between subgroups based on different diagnostic criteria.” All included studies in this review, however, used the Oxford or Fukuda criteria which do not require PEM. In other words, the subgroup analysis compared the Oxford versus Fukuda criteria, not those two criteria versus more recent case definitions that do require PEM.

Risk of bias
The NICE committee noted that GET-trials focused on subjective outcomes even though neither patients nor therapists could be blinded to treatment allocation. This combination was considered an important limitation when interpreting the evidence.
The figures cited by Busse and colleagues compare GET to a passive control condition where patients received less time and attention from healthcare providers. Patients in the GET-group also received instructions to interpret their symptoms as less threatening and more benign. According to one therapist manual on GET “participants are encouraged to see symptoms as temporary and reversible, as a result of their current physical weakness, and not as signs of progressive pathology.” Treatment manuals also included strong assertions designed to strengthen patients’ expectations of GET. One patient booklet stated: “You will experience a snowballing effect as increasing fitness leads to increasing confidence in your ability. You will have conquered CFS by your own effort and you will be back in control of your body again.” Patients in the control group received no such instructions. There is therefore a reasonable concern that the reduction on fatigue questionnaires in the GET group reflects response bias rather than a genuine reduction in fatigue. Other reviews have previously come to a similar conclusion.
Busse and colleagues, however, argue that lack of blinding should not result in downgrading quality of evidence, even if subjective outcomes are used as the primary outcome. This is a statement that has far-reaching implications. It would either mean that drug trialists should no longer attempt to blind patients and therapists (because this wouldn’t affect the quality of evidence) or that behavioral interventions should be treated as an exception where risk of response bias can freely be ignored because it is practically not feasible to blind patients and therapists.
If the GRADE system was used as Busse and colleagues recommend, there would be a high risk that quack treatments and various forms of pseudo-science also provide ‘reliable’ evidence of effectiveness in randomized trials. All that is needed is an intervention where therapists actively manipulate how patients interpret and report their symptoms. One example should suffice to clarify this point.
Suppose an intervention based on ‘neurolinguistic programming’ where therapists assume that saying one is fatigued, reinforces neural circuits that perpetuate fatigue. The intervention consists of breaking this vicious cycle by encouraging patients to no longer see or report themselves as fatigued. This example is not that far-fetched as there are already behavioral interventions for ME/CFS that are based on similar principles. According to the GRADE methodology specified by Busse et al., however, such attempts to manipulate how patients report their symptoms, form no reason to downgrade the quality of evidence of randomized trials, even if fatigue questionnaires are used as the primary outcome.
Conclusion: where did they go wrong?
In conclusion, criticism that the NICE committee used “a disastrous misapplication of GRADE methodology” to come to “nihilistic conclusions” is unsubstantiated. The NICE committee followed GRADE methodology sensibly, while Busse and colleagues seem to have come up with arbitrary rules that risk rating quackery as an effective treatment.
The first and foremost principle of rating quality of evidence should be to understand the specifics of what is being assessed. One has to understand the nature of the intervention and how it is supposed to impact patients. By providing a standardized checklist and algorithm to assess quality of evidence, the GRADE methodology risks discouraging researchers from studying the details of what happens in randomized trials. The rapid response by Busse and colleagues is an example of how this approach can result in questionable treatment recommendations.
Great and interesting! (I see that you refer to our recent paper 🙂 Wormgoor and Rodenburg
Thank you for an excellent blog in general, and also a really solid blog post. You are a voice of reason, logic and levelheadedness in an ocean of confusion, politics and outdated ideologies.
When you see both the names Paul Garner and Signe Flottorp on the article, you know what the conclusion will be even before you start reading the first paragraph. Signe has been a very strong and unbalanced proponent of the BPS ideology ever since she started to get into the field, and has made some very strange claims throughout the years. She’s even gone so far as to say that any ME-patients that report harm from the Lightning Process are “ME-activists” who are trying to manipulate government bodies. I don’t know if she’s more balanced and nuanced in other areas of medicine, but when it comes to ME/CFS she seems rather extreme. She’s also a good friend of the “psychology PhD from Norway” (Live Landmark) that Paul described in his now infamous recovery story in the BMJ. Live is also a Lightning Process coach, by the way, who’s said some rather extreme things through the years and seems to harbour a deep resentment towards pwME.
Paul Garner himself is, of course, newer to the field, given how he got into it after his bout with Covid. When I read his newer writings it seems like he posesses the devotion of a born again Christian coming back to his childhood faith after a brief period of agnosticism. It seems like reason and logic has been cast aside – and what’s important to him now is to prove his devotion to the “true faith” – the BPS ideology.